Software Is Used in a Linux Environment to Mount and Write Data Only to Ntfs Partitions
It's a bit tricky to explain what exactly a file system is in just one sentence.
That's why I decided to write an article about it. This post is meant to be a high-level overview of file systems, but I'll sneak into the lower-level concepts as well. As long as it doesn't get boring. :)
What is a file system?
Let's start with a simple definition:
A file system defines how files are named, stored, and retrieved from a storage device.
When people talk about file systems, they might refer to different aspects of a file system depending on the context - that's where things start to seem knotty.
And you might end up asking yourself, WHAT IS A FILE SYSTEM ANYWAY? 🤯
In this guide, I'll help you understand file systems and any conversation about file systems. I'll also cover partitioning and booting as well, to help you understand the concepts surrounding file systems.
To keep this guide manageable, I'll concentrate on Unix-like environments when explaining the lower-level structures or console commands. However, the concepts remain relevant to other environments and file systems.
Why do we need a file system in the first place, you may ask?
Well, without a file system, the storage device would contain a big hunk of data stored back to back, and you wouldn't be able to tell them apart.
The term file system takes its name from the old paper-based data management systems, where we kept documents as files, and put them into directories.
Imagine a room with piles of papers scattered all over the place.

A storage device without a file system would be in the same situation - and it would be a useless electronic device.
However, a file system changes everything:

A file system isn't just a bookkeeping feature, though.
Space management, metadata, data encryption, file access control, and data integrity are the responsibilities of file system too.
Everything begins with partitioning
Storage devices must be partitioned and formatted before the first use.
But what is partitioning?
Partitioning is splitting a storage device into several logical regions, so they can be managed separately as if they are separate storage devices.
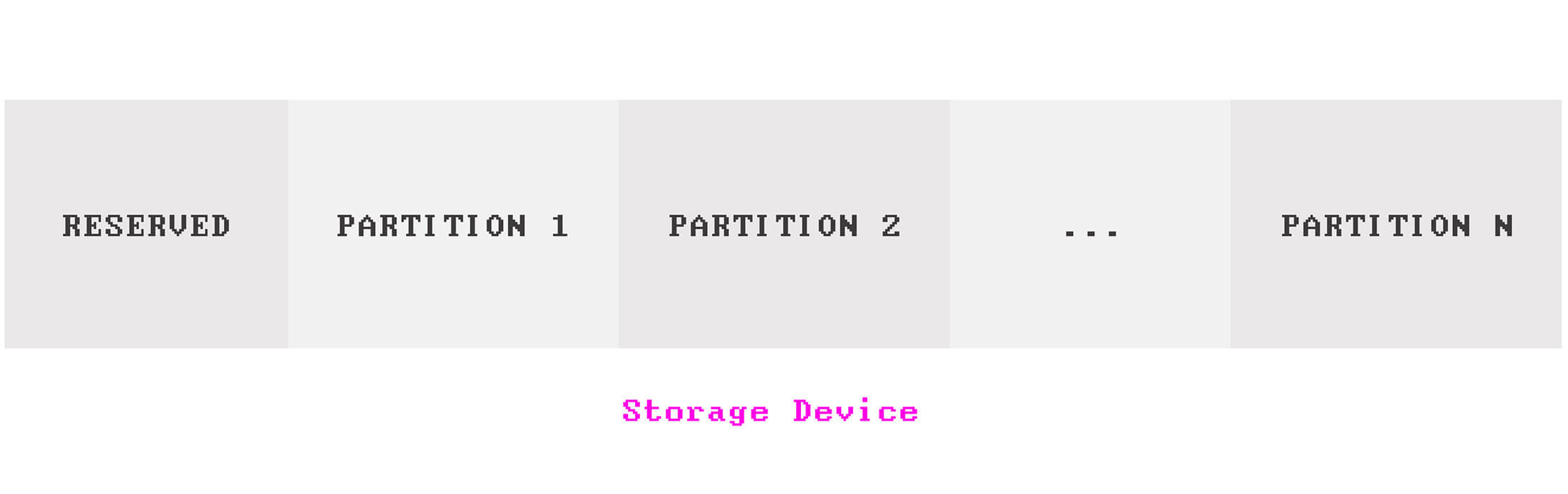
Partitioning is done by a disk management tool provided by operating systems, or a as text-based CLI tool provided by the system's firmware.
A storage device should have at least one partition, or more, if needed.
For example, a basic Linux installation has three partitions: one partition dedicated to the operating system, one partition for user files, and a swap partition.
Windows and Mac OS also have similar layout, although they don't use a dedicated swap partition. Instead, they manage swapping within the partition the operating system is installed on.
So why should we split the storage devices into multiple partitions?
The reason is that we don't want to manage and use the whole storage space as a single unit, and for a single purpose.
It's just like how we partition our workspace, to separate (and isolate) meeting rooms, conference rooms, and teams.

On a computer with multiple partitions, you can install multiple operating systems and every time choose a different partition to boot up your system with.
The recovery and diagnostic utilities reside in dedicated partitions too.
For instance to boot up a MacBook in recovery mode, you need hold Command + R as soon as you restart (or turn on) your MacBook.
By doing so, you're instructing the system to boot up with a partition that contains the recovery program.
Partitioning isn't just a way of installing multiple operating systems and tools, though. It also allows us to keep critical system files apart from ordinary files.
So no matter how many heavy games you install on your computer, it won't have any affect on the operating system's performance - since they reside in different partitions.
Back to the office example, having a call center and a tech team in a common area would have a negative effect on both team's productivity, because each team has their own requirements to be efficient.
For instance, the tech team would appreciate a quieter area.
Some operating systems, like Windows, assign a drive letter (A, B, C, or D) to the partitions. For instance the primary partition on Windows (on which Windows is installed) is referred to as C:, or drive C.
In Unix-like operating systems, however, partitions appear as normal directories under the root directory - we'll cover this later.
Guess what? W're taking a detour here ↩️
In the next section, we'll dive deeper into partitioning, and get to know two concepts that will change your perspective on file systems: system firmwares and booting.
Are you ready?
Away we go! 🏊♂️
Partitioning schemes, system firmwares, and booting
When partitioning a storage device, we have two partitioning methods to choose from:
- Master boot record (MBR) Scheme
- GUID Partition Table (GPT) Scheme
Regardless of what partitioning scheme you choose, the first few blocks on the storage device will always contain critical data about your partitions.
The system's firmware uses these data structures to boot up the operating system.
Wait, what is the system firmware? you may ask.
Here's an explanation:
A firmware is a low-level software embedded into electronic devices to operate the device, or bootstrap another program to operate the device.
Firmware exists in computers, peripherals (keyboards, mouse, and printers), or even electronic home appliances.
In computers, the firmware provides a standard environment for a complex software like an operating system to boot up and work with hardware components.
However, on simpler systems like a printer, the firmware is the main operating system of the device. The printer menu is the interface of its firmware.
Computer firmwares are implemented based on two specifications:
- Basic Input/Output (BIOS)
- Unified Extensible Firmware Interface (UEFI)
Firmwares - BIOS-based or UEFI-based - reside on a non-volatile memory, like a flash ROM attached to the motherboard.

When you power on your computer, the firmware is the first program to run.
The mission of the firmware (among other things) is to boot up the computer, run the operating system, and pass it the control of the whole system.
A firmware also runs pre-OS environments (with network support), like recovery or diagnostic tools, or even a special shell to run text-based commands.
The first few screens you see before your operating system's logo appears are the output of your computer's firmware, verifying the health of hardware components and the memory.
The initial check is confirmed with a beep, indicating everything is good to go.
MBR partitioning scheme is a part of the BIOS specifications, and used by BIOS-based firmwares.
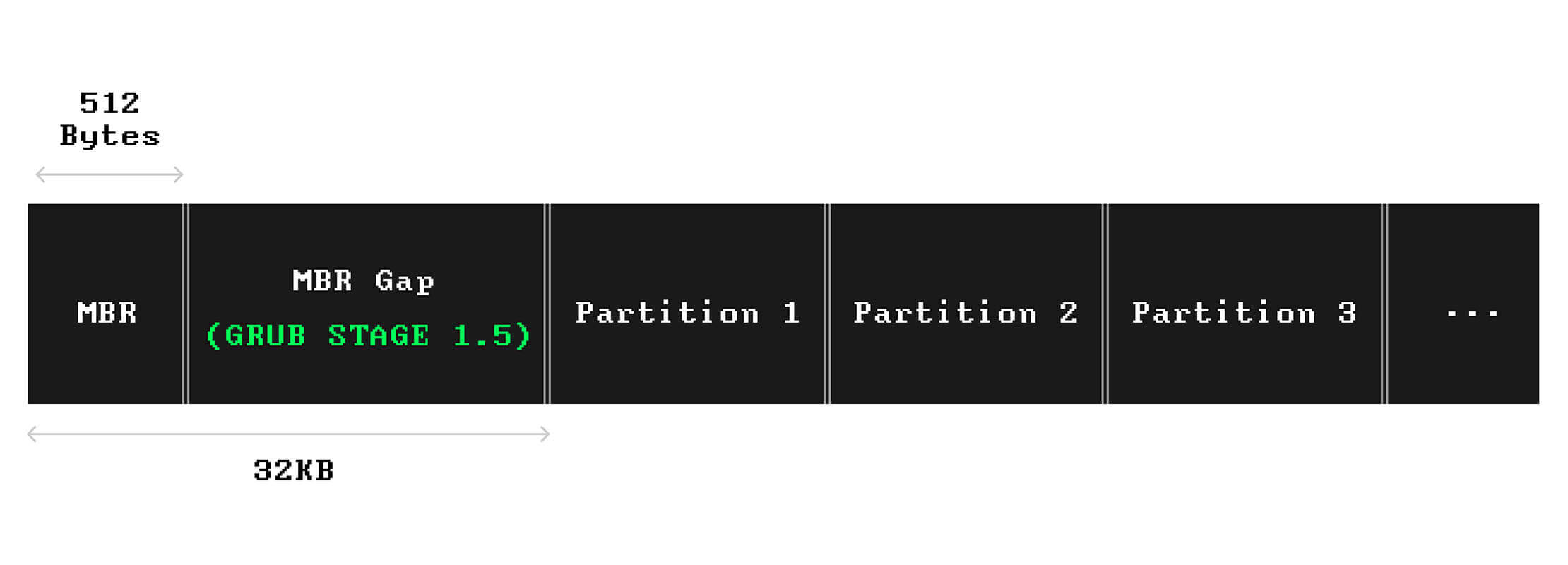
On MBR-partitioned disks, the first sector on the storage device contains essential data to boot up the system.
This sector is called MBR.
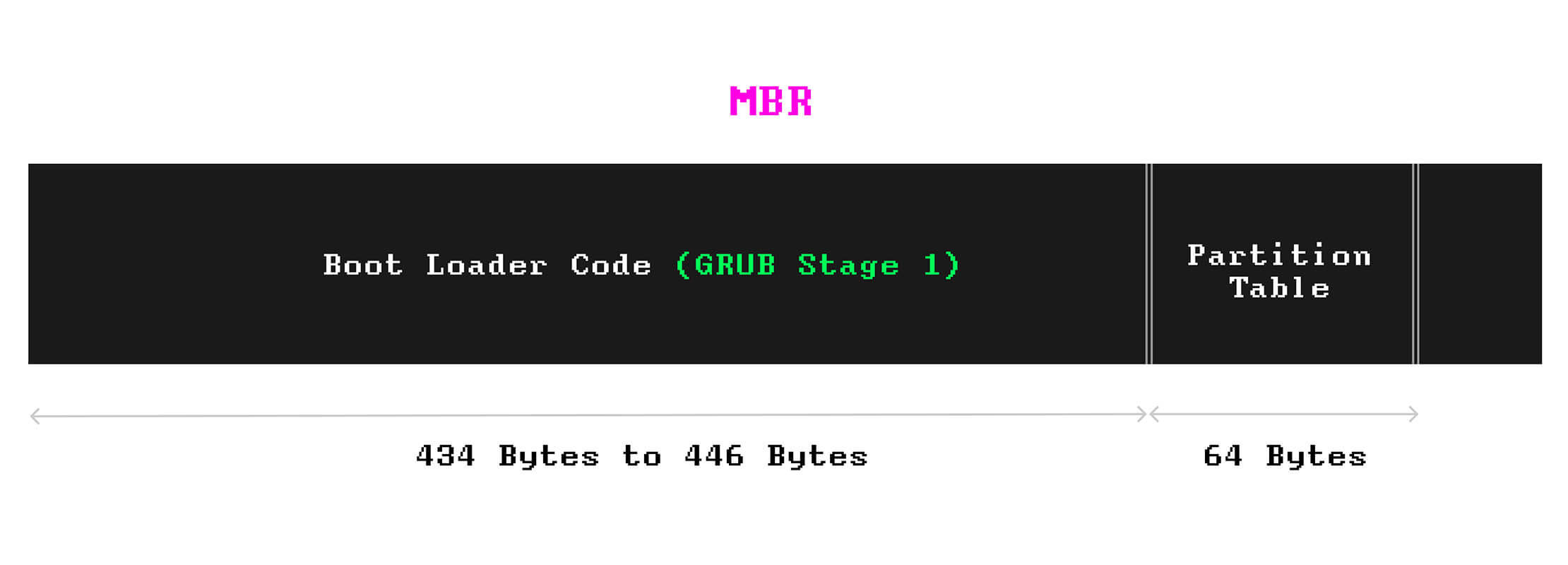
MBR contains the following information:
- The boot loader, which is a simple program (in machine code) to initiate the first stage of the booting process
- A partition table, which contains information about your partitions.
BIOS-based firmwares with MBR-partitioned disks boot the system differently than UEFI-based firmwares.
Here's how it works:
Once the system is powered on, the BIOS firmware starts and loads the content of MBR into the memory, and runs the boot loader inside it.
Having the boot loader and the partition table in a predefined location like MBR enables BIOS to boot up the system without having to deal with any file.
The boot loader code in the MBR takes between 434 bytes to 446 bytes of the MBR (out of 512b). 64 bytes is also allocated to the partition table for a maximum of four partitions.
446 bytes isn't big enough to accommodate too much code, though. That said, sophisticated boot loaders like GRUB 2 on Linux split their functionality into pieces, or stages.
The smallest piece, which is known as the first-stage boot loader, sits within the MBR.
The first-stage boot loader initiates the next stages of the booting process.
Immediately after the MBR, and before the first partition, there's a small space, around 1MB, called the MBR gap. It can be used to place another piece of the boot loader, if needed.
A boot loader, such as GRUB 2, uses the MBR gap to store another stage of its functionality. GRUB calls this the stage 1.5 boot loader, which contains a file system driver.
The stage 1.5 enables the next stages of GRUB to work with files, rather than loading raw data from the storage device (like the first-stage boot loader).
The second stage boot loader, which is now file-system-aware, can load the operating system's boot loader file to boot up the operating system.
This is when the operating system's logo fades in...
Here's the layout of an MBR-partition storage device:
An if we magnify the MBR, its content would look like this:
Although MBR is very simple and widely supported, it has some limitations.
MBR's data structure limits the number of partitions to only four primary partitions.
A common workaround is to make an extended partition beside the primary partitions, as long as the total number of partitions won't exceed four.
An extended partition can be split into multiple logical partitions.
When making a partition you can choose between primary and extended.
After this is solved, we'll encounter the second limitation.
Each partition can be maximum of 2TiB.
And wait, there's more!
The content of MBR sector has no back up 😱, meaning if MBR gets corrupted due to an unexpected reason, we'll have a useless storage device.
The GPT partitioning scheme is more sophisticated than MBR, and doesn't have the limitations MBR has.
For instance, you can have as many partitions as your operating systems allows.
And every partition can be the size of the biggest storage device available in the market - actually a lot more.
GPT is gradually replacing MBR, although MBR is still widely supported across both old PC's and new.
As mentioned earlier, GPT is a part of the UEFI specification, which is replacing the good old BIOS.
That means that UEFI-based firmwares use a GPT-partitioned storage device to perform the booting.
Many hardware and operating systems now support UEFI and use the GPT scheme to partition storage devices.
In the GPT partitioning scheme, the first sector of the storage device is reserved for compatibility reasons with BIOS-based systems. This is because some systems might still use a BIOS-based firmware but have a GPT-partitioned storage device.
This sector is called Protective MBR. (This is where the first-stage boot loader would reside in an MBR-partitioned disk)
After this first sector, the GPT data structures are stored, including the GPT header and the partition entries.
As a backup, the GPT entries and the GPT header are also stored at the end of the storage device, so it can be recovered if the main copy gets corrupted. This backup is called Secondary GPT.
The layout of a GPT-partitioned storage device looks like this:

In GPT, all the booting services (boot loaders, boot managers, pre-os environments, and shells) live in a special partition called EFI System Partition (ESP), which UEFI firmware can use.
ESP even has it own file system, which is a specific version of FAT. On Linux, ESP resides under the /sys/firmware/efi path.
If this path cannot be found on your system, then you firmware is probably a BIOS-based firmware.
To check you can try to change the directory to the ESP mount point, like so:
cd /sys/firmware/efi UEFI-based firmware assumes that the storage device is partitioned with GPT, and looks up the ESP in the GPT partition table.
Once the EFI partition is found, it looks for the configured boot loader, which is normally a file ending with .efi.
UEFI-based firmware gets the booting configuration from NVRAM (which is non-volatile RAM). NVRAM contains the booting settings as well as paths to the operating system boot loaders.
UEFI firmwares are also capable of performing BIOS-boot (to boot the system from an MBR disk) if configured accordingly.
You can use the parted command on Linux to see what partitioning scheme is used for a storage device.
sudo parted -l And the output would be something like this:
Model: Virtio Block Device (virtblk) Disk /dev/vda: 172GB Sector size (logical/physical): 512B/512B Partition Table: gpt Disk Flags: Number Start End Size File system Name Flags 14 1049kB 5243kB 4194kB bios_grub 15 5243kB 116MB 111MB fat32 msftdata 1 116MB 172GB 172GB ext4 Based on the above output, the storage device's ID is /dev/vda with the capacity of 172GB.
The storage device is partitioned based on GPT, and has three partitions. The second and third partitions are formatted based on the FAT32 and EXT4 file systems respectively.
Having a BIOS GRUB partition implies the firmware is a BIOS-based firmware.
Let's confirm that with the dmidecode command like so:
sudo dmidecode -t 0 And the output would be:
# dmidecode 3.2 Getting SMBIOS data from sysfs. SMBIOS 2.4 present. ... ✅ Confirmed!
When partitioning is done, the partitions should be formatted.
Most operating systems allow you to format a partition based on a set of file systems.
For instance, if you are formatting a partition on Windows, you can choose between FAT32, NTFS, and exFAT file systems.
Formatting involves the creation of various data structures and metadata used to manage files within a partition.
These data structures are one aspect of a file system.
Let's take the NTFS file system as an example.
When you format a partition to NTFS, the formatting process places the key NTFS data structures, as well as Master file table (MFT), on the partition.
Alright, enough about partitioning and booting. Let's get back to file systems.
How it started, how it's going
A file system is a set of data structures, interfaces, abstractions and APIs that work together to manage any type of file on any type of storage device, in a consistent manner.
Each operating system uses a particular file system to manage the files.
In the early days, Microsoft used FAT (FAT12, FAT16, and FAT32) in the MS-DOS and Windows 9x family.
Starting from Windows NT 3.1, Microsoft developed New Technology File System (NTFS), which had many advantages over FAT32, such as supporting bigger files, longer filenames, data encryption, access management, journaling, and a lot more.
NTFS has been the default file system of the Window NT family (2000, XP, Vista, 7, 10, etc) since then.
NTFS isn't suitable for non-Windows environments, though.
For instance, you can only read the content of an NTFS-formatted storage device (like flash memory) on a Mac OS, but you won't be able to write anything to it - unless you install a NTFS driver with write support.
Extended File Allocation Table (exFAT) is a lighter version of NTFS created by Microsoft in 2006.
exFAT was designed for high-capacity removable devices, such as external hard disks, USB drives, and memory cards.
exFAT is the default file system used by SDXC cards.
Unlike NTFS, exFAT has read and write support on Non-Windows environments as well , including Mac OS — making it the best cross-platform file system for high-capacity removable storage devices.
So basically, if you have a removable disk you want to use on Windows, Mac, and Linux, you need to format it to exFAT.
Apple has also developed and used various file systems over the years, including
Hierarchical File System (HFS), HFS+, and recently Apple File System (APFS).
Just like NTFS, APFS is a journaling file system, and has been in use since the launch of OS X High Sierra in 2017.
The Extended File System (ext) family of file systems was specifically created for the Linux kernel - the core of the Linux operating system.
The first version of ext was released in 1991 but soon after it was replaced by the second extended file system (ext2) in 1993.
In the 2000s the third extended filesystem (ext3) and fourth extended filesystem (ext4) were developed for Linux with journaling capability.
ext4 is now the default file system in many distributions of Linux, including Debian and Ubuntu.
You can use the findmnt command on Linux to list your ext4-formatted partitions:
findmnt -lo source,target,fstype,used -t ext4 The output would be something like:
SOURCE TARGET FSTYPE USED /dev/vda1 / ext4 3.6G Architecture of file systems
The anatomy of a file system within an operating system consists of three layers:
- Physical file system
- Virtual file system
- Logical file system.
These layers can be implemented as independent or tightly coupled abstractions.
When people talk about file systems, they refer to one of these layers.
Although these layers are different across operating systems, the concept is pretty much the same.
The physical layer is the concrete implementation of a file system. It is responsible for data storage and retrieval, as well as space management on the storage device.(or more precisely partitions)
The physical file system interacts with the actual storage hardware, via device drivers.
The next layer is the virtual file system, or VFS.
The virtual file system provides a consistent view of various file systems mounted on the same operating system.
So does this mean an operating system can use multiple file systems at the same time?
The answer is yes!
It's common for a removable storage medium to have a different file system than that of the computer.
For instance, on Windows (which uses NTFS as the main file system), a flash memory might have been formatted to exFAT or FAT32.
That said, the operating system should provide a unified interface - a consistent view - between programs (file explorers and other apps that work with files) and the different mounted file systems (such as NTFS, APFS, EXT4, FAT32, exFAT, and UDF).
For instance, when you open up your file explorer program, you can copy an image from an EXT4 file system, and paste it over to your exFAT-formatted flash memory - without having to know that files are managed differently under the hood.
This convenient layer between the user (you) and the underlying file systems is provided by the VFS.
A VFS defines a contract that all physical file systems must implement to be supported by the operating system.
However, this compliance isn't built into the file system core, meaning the source code of a file system doesn't include support for every operating system.
Instead it uses a file system driver to adhere to the VFS rules.
A driver is a special program that enables a software to communicate with another software or hardware.
User programs don't directly interact with the VFS, though.
Instead, they use a unified API, which sits between programs and the VFS.
Yes, we're talking about the logical file system.
The logical file system is the user facing part of a file system, which provides an API to enable user programs to perform various file operations, such as OPEN, READ, and WRITE , without having to deal with any storage hardware.
On the other hand, VFS provides a bridge between the logical layer (which programs interact with) and a set of physical file systems.

What does it mean to mount a file system?
On Unix-like systems, the VFS assigns a device ID (for example dev/disk1s1) to each partition or removable storage device.
Then, it creates a virtual directory tree and puts the content of each device under that directory tree as separate directories.
The act of assigning a directory to a storage device (under the root directory tree) is called mounting, and the assigned directory is called a mount point.
That said, on a Unix-like operating system, all partitions and removable storage devices appear as if they are directories under the root directory.
For instance, on Linux, the mounting point for a removable device (such as a memory card), is /media (relative to the root directory) by default - unless configured otherwise.
That said, once a flash memory is attached to the system, and consequently, auto mounted at the default mounting point (/media in this case), its content would be available under /media directory .
However, there are times you need to mount a file system manually.
On Linux, it's done like so:
mount /dev/disk1s1 /media/usb In the above command, the first parameter is the device ID (/dev/disk1s1), and the second parameter (/media/usb) is the mount point.
Please note that the mount point should already exist as a directory.
If it doesn't, it has to be created first:
mkdir -p /media/usb mount /dev/disk1s1 /media/usb File metadata is a data structure that contains data about a file, such as:
- File size
- Timestamps, like creation date, last accessed date, and modification date
- The file's owner
- The file's mode (who can do what with the file)
- What blocks on the partition are allocated to the file
- and a lot more
Metadata isn't stored with the file content, though. Instead, it's stored in a different place on the disk - but associated with the file.
In Unix-like systems, the metadata is in the form of special data structures, called inode.
Inodes are identified by a unique number called the inode number.
Inodes are associated with files in a data structure called inode tables.
Each file on the storage device has an inode, which contains information about the file, including the address of the blocks allocated to the file.
In an ext4 inode, the address of the allocated blocks is stored as a set of data structures called extents (within the inode).
Each extent contains the address of the first data block allocated to the file, and the number of the next continuous blocks that the file has occupied.
If the file is fragmented, each fragment will have its own extent.
This is different than ext3's pointer system, which points to individual data blocks via indirect pointers.
Using an extent data structure enables the file system to point to large files without taking up too much space.
Whenever a file is requested, its name is first resolved to an inode number.
Having the inode number, the file system fetches the respective inode from the storage device.
Once the inode is fetched, the file system starts to compose the file from the data blocks stored in the inode.
You can use the df command with the -i parameter on Linux to see the inodes (total, used, and free) in your partitions:
df -i The output would look like this:
udev 4116100 378 4115722 1% /dev tmpfs 4118422 528 4117894 1% /run /dev/vda1 6451200 175101 6276099 3% / As you can see, the partition /dev/vda1 has a total number of 6451200, of which 3% have been used (175101 inodes).
Additionally, to see the inodes associated with files in a directory, you can use the ls command with -il parameters.
ls -li And the output would be:
1303834 -rw-r--r-- 1 root www-data 2502 Jul 8 2019 wp-links-opml.php 1303835 -rw-r--r-- 1 root www-data 3306 Jul 8 2019 wp-load.php 1303836 -rw-r--r-- 1 root www-data 39551 Jul 8 2019 wp-login.php 1303837 -rw-r--r-- 1 root www-data 8403 Jul 8 2019 wp-mail.php 1303838 -rw-r--r-- 1 root www-data 18962 Jul 8 2019 wp-settings.php The first column is the inode number associated with each file.
The number of inodes on a partition is decided when the partition is formatted. So as long as there's free space and there are unused inodes, files can be stored on the storage device.
It's unlikely that a personal Linux OS would run out of inodes. However, enterprise services that deal with a large number of files (like mail servers) have to manage their inode quota smartly.
On NTFS, the metadata is stored differently, though.
NTFS keeps file information in a special data structure called the Master File Table (MFT).
Every file has at least one entry in MFT, which contains everything about the respective file, including its location on the storage device - similar to inodes.
On most operating systems, general file metadata can be accessed from the graphical user interface as well.
For instance, when you right-click on a file on Mac OS, and select Get Info (Properties in Windows), a window appears with information about the file. This information is fetched from the respective file's metadata.
Space Management
Storage devices are divided into fixed-sized blocks called sectors.
A sector is the minimum storage unit on a storage device, and is between 512 bytes and 4096 bytes (Advanced Format).
However, file systems use a high-level concept as the storage unit, called blocks.
Blocks are an abstraction over physical sectors and consist of multiple sectors.
Depending on the size of a file, the file system allocates one or more blocks to each file.
Speaking of space management, the file system is aware of every used and unused block on the partitions, so it'll be able to allocate space to new files or fetch the existing ones when requested.
The most basic storage unit in ext4-formatted partitions is the block.
However, the contiguous blocks are grouped into block groups for easier management.

Each block group has its own data structures and data blocks.
Here are the data structures a block group can contain:
- Super Block: a metadata repository, which contains meta data about the entire file system, such as total number of blocks in the file system, total blocks in block groups, inodes, and more. Not all block groups contain the super block, though. A certain number of block groups store a copy of the super as a backup.
- Group Descriptors: Group descriptors also contain bookkeeping information for each block group
- Inode Bitmap: Each block group has its own inode quota for storing files. A block bitmap is a data structure used to identify used and unused inodes within the block group.
1denotes used and0denotes unused inode objects. - Block Bitmap: a data structure used to identify used and unused data blocks within the block group.
1denotes used and0denotes unused data blocks - Inode Table: a data structure which defines the relation of files and their inodes. The number of inodes stored in this area is related to the block size used by the file system.
- Data Blocks: This is the zone within the block group where file contents are stored.
Ext4 file systems even take one step further (comparing to ext3), and organise block groups into a bigger group called flex block groups.
Each flex box group contains a number block groups.
The data structures of each block group, including the block bitmap, inode bitmap, and inode table, are concatenated and stored in the first block group within the respective flex block group.
Having all the data structures concatenated in one block group (the first one) frees up more contiguous data blocks on other block groups within each flex block group.
The layout of the first block group looks like this:
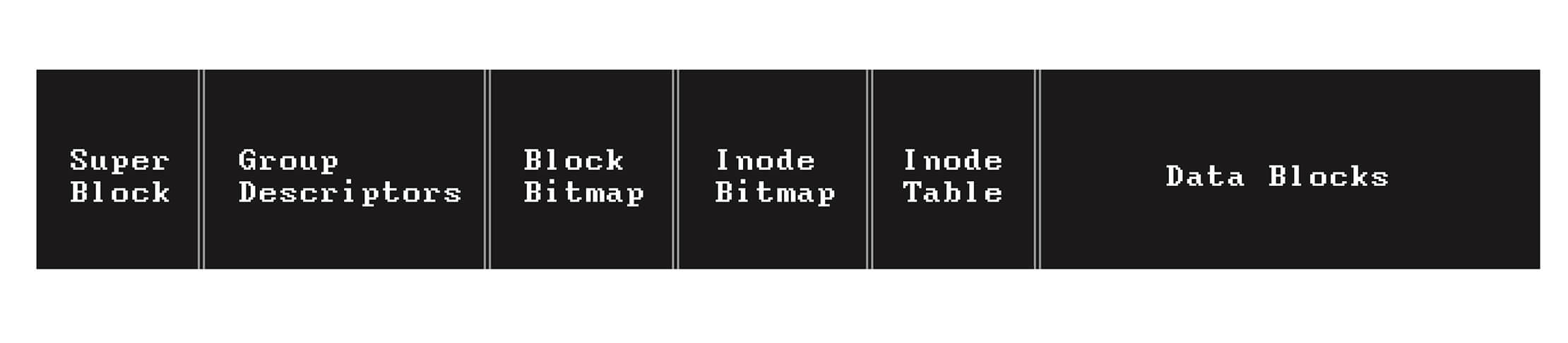
When a file is being written to a disk it is written to a one or more blocks within a certain block group.
Managing files in block group level significantly improves the performance of the file system.
Size vs size on disk
Have you ever noticed that your file explorer displays two different sizes for each file: size, and size on disk.
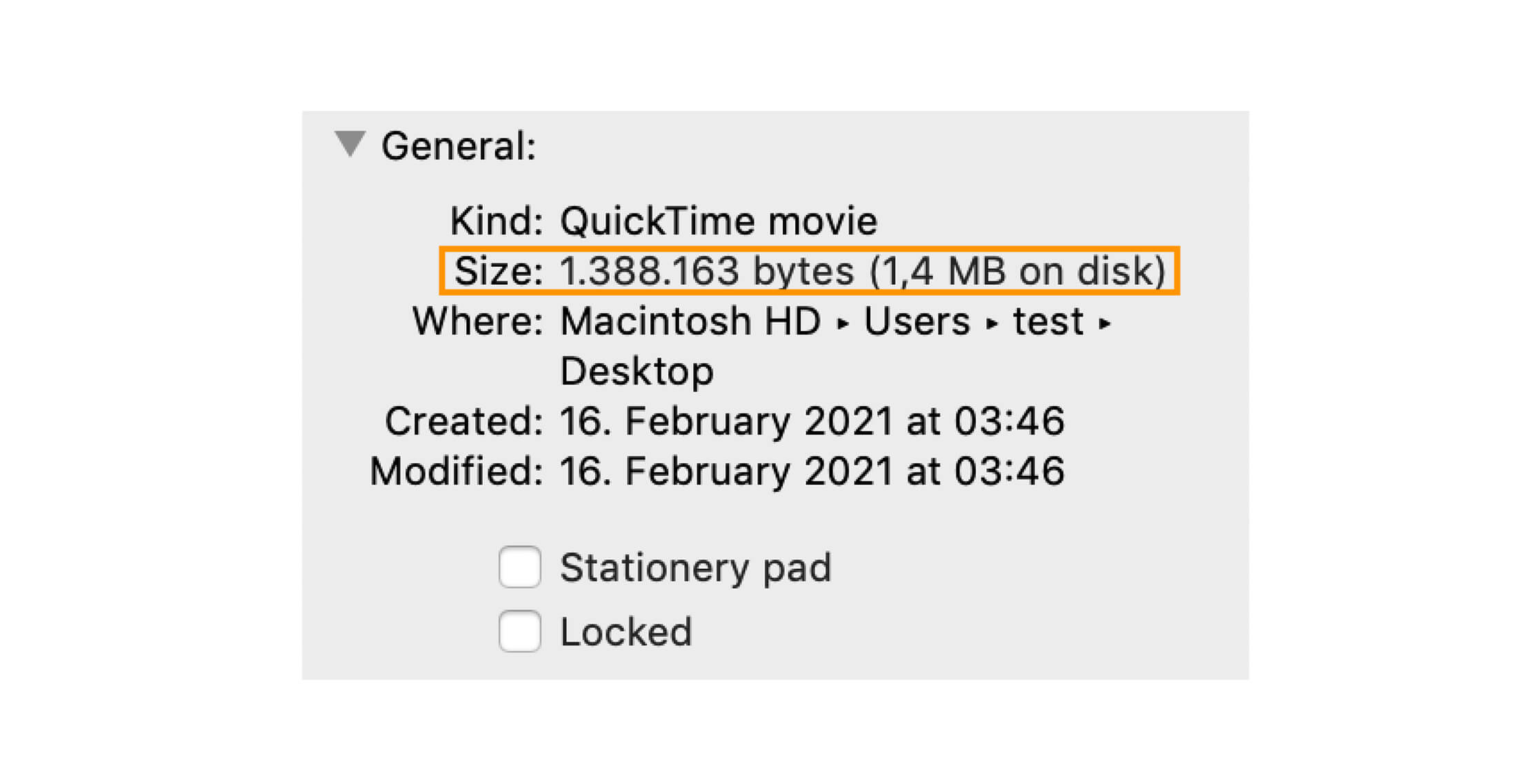
Why are size and size on disk slightly different? You may ask.
Here's an explanation:
We already know that, depending on the file size, one or more blocks are allocated to a file.
One block is the minimum space that can be allocated to a file. This means the remaining space of a partially-filled block cannot be used by another file.
Since the size of the file isn't an integer multiple of blocks, the last block might be partially used, and the remaining space would remain unused - or would be filled with zeros.
So "size" is basically the actual file size, while "size on disk" is the space it has occupied, even though it's not using it all.
You can use du command on Linux to see it for yourself.
du -b "some-file.txt" The output would be something like this:
623 icon-link.svg And to check the size on disk:
du -B 1 "icon-link.svg" Which will result in:
4096 icon-link.svg Based on the output, the allocated block is about 4kb, while the actual file size is 623 bytes.
What is disk fragmentation?
Over time, new files are written to the disk, existing files increase in size, are shrunk, or are deleted.
These frequent changes in the storage medium leave many small gaps (empty spaces) between files.
File Fragmentation occurs when a file is stored as fragments on the storage device because the file system cannot find enough contiguous blocks to store the whole file in a row.
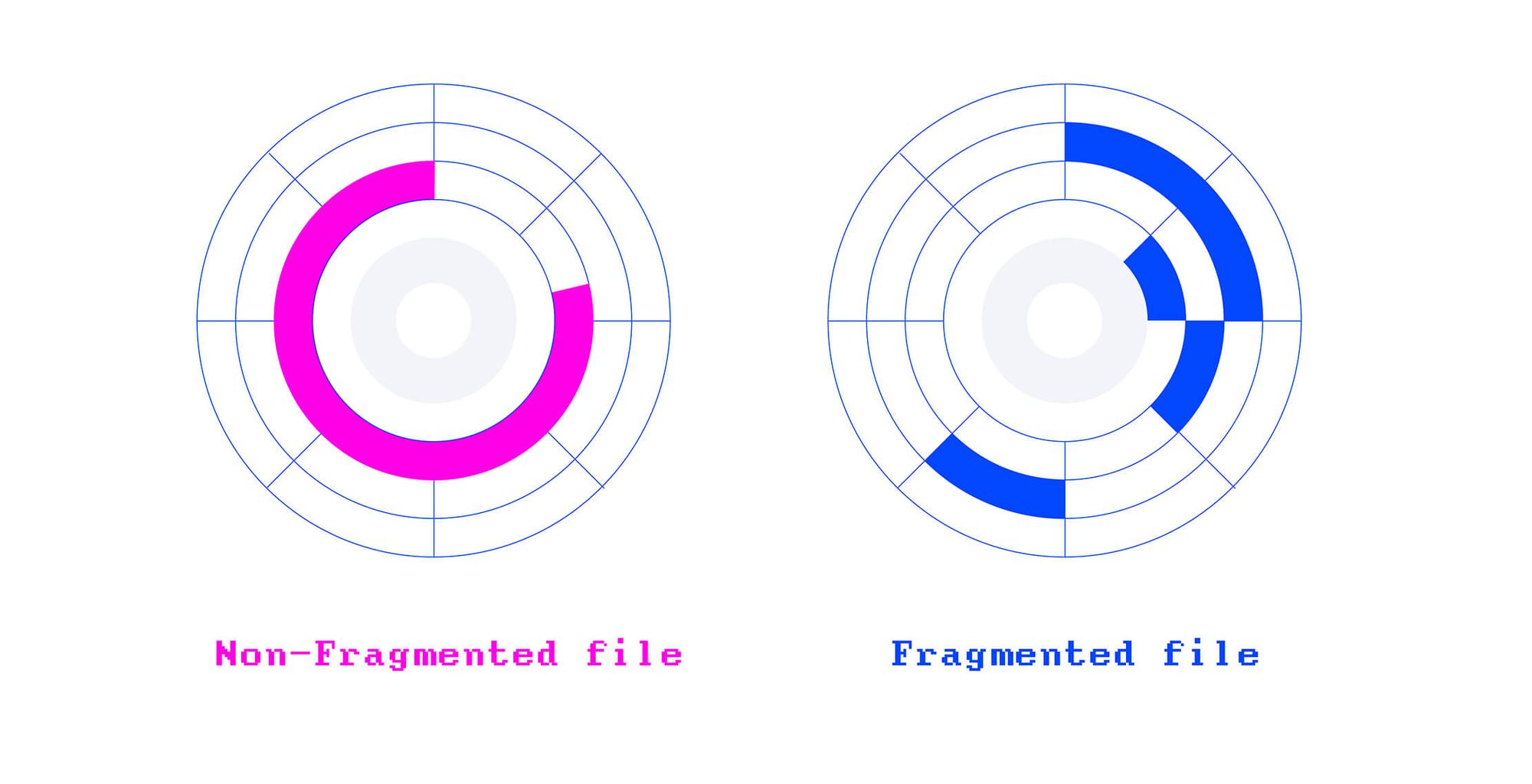
Let's make it more clear with an example.
Imagine you have a Word document named myfile.docx.
myfile.docx is initially stored in a few contiguous blocks on the disk, let's say LBA250, LBA251, and LBA252 - by the way, this naming is hypothetical.
Now, if you add more content to myfile.docx and save it, it will need to occupy more blocks on the storage medium.
Since myfile.docx is currently stored on LBA250, LBA251, and LBA252, the new content should preferably sit within LBA253 and so forth - depending on how much space is needed.
However, if LBA253 is already taken by another file (maybe it's the first block of another file), the remaining content of myfile.docx has to be stored on different blocks somewhere else on the disks, for instance, LBA312 and LBA313.
myfile.docx got fragmented 💔.
File fragmentation puts a burden on the file system because every time a fragmented file is requested by a user program, the file system needs to collect every piece of the file from various locations on disk.
The applies to saving the file back to the disk as well.
The fragmentation might also occur when a file is written to the disk for the first time, probably because the file is huge, and not much space is left on the storage device.
Fragmentation is one of the reasons some operating systems get slow as the file system ages.
Should We Care About Fragmentation these days?
The short answer is: not anymore!
Modern file system use smart algorithms to avoid (or early detect) fragmentation as much as possible.
Ext4 also does some sort of preallocation, which involves reserving blocks for a file before they are actually needed - making sure the file won't get fragmented if it get bigger over time.
The number of the preallocated blocks is defined in the length field of the file's extent of its inode object.
Additionally, Ext4 uses an allocation technique called delayed allocation.
The idea is instead of writing to data blocks one at a time during a write, the allocation requests are accumulated in a buffer. Finally, the allocation is done and data is written to the disk.
Not having to call the block allocator on every write request helps the file system make better choices with distributing the available space. For instance, by placing large files apart from smaller files.
Imagine that a small file is located between to large files. Now, if the small file is deleted, it leaves a small space between the two files.
If the big files and small files are kept in different areas on the storage device, when a file deletes small files won't leave many gaps on the storage device.
Spreading the files out in this manner leaves enough gaps between data blocks, which helps the filesystem manage (and avoid) fragmentation more easily.
Delayed allocation actively reduces fragmentation and increases performance.
Directories
A Directory (Folder in Windows) is a special file used as a logical container to group files and directories.
On NTFS and Ext4, directories and files are treated the same way. That said, directories are just files that have their own inode (on Ext4) or MFT entry (on NTFS).
The inode or MFT entry of a directory contains information about that directory, as well as a collection of entries pointing to the files associated with that directory.
The files aren't literally contained within the directory, but they are associated to the directory in a way that they appear as directory's children in a higher level - like a file explorer program.
These entries are called directory entries. Directory entries contain file names mapped to their inode/MFT entry.
In addition to the directory entries, two other entries also exist, ., which points the directory itself, and .., which points to its parent directory.
On Linux, you can use the ls in a directory to see the directory entries with their associated inode numbers:
ls -lai And the output would be something like this:
63756 drwxr-xr-x 14 root root 4096 Dec 1 17:24 . 2 drwxr-xr-x 19 root root 4096 Dec 1 17:06 .. 81132 drwxr-xr-x 2 root root 4096 Feb 18 06:25 backups 81020 drwxr-xr-x 14 root root 4096 Dec 2 07:01 cache 81146 drwxrwxrwt 2 root root 4096 Oct 16 21:43 crash 80913 drwxr-xr-x 46 root root 4096 Dec 1 22:14 lib ... Filename Rules
Some file systems enforce limitations on filenames.
The limitation can be on the length of the filename or filename case sensitivity.
For instance, in NTFS file system, MyFile and myfile refer to the same file, while on EXT4, they point to different files.
Why does this matter? you may ask.
Imagine that you're creating a web page on your Windows machine. The web page contains your brand logo, a PNG file, like this:
<!DOCTYPE html> <html> <head> <title>Products - Your Website</title> </head> <body> <!--SOME CONTENT--> <img src="img/logo.png"> <!--SOME MORE CONTENT--> </body> </html> Even if the actual file name is Logo.png (note the capital L), you can still see the image when you open your web page on your web browser.
However, once you deploy it to a Linux server, and view it live, the image would be broken.
Why?
Because in Linux (EXT4 file system) logo.png and Logo.png point to two different files.
File Size Rules
One important aspects of file systems is their supported maximum file size.
An old file system like FAT32, (used by MS-DOS +7.1, Windows 9x family, and flash memories) can't store files more than 4 GB, while its successor, NTFS allows file sizes to be up to 16 EB (1000 TB).
Just like NTFS, exFAT allows a file size of 16 EB as well, which makes it an ideal choice for storing massive data objects, such as video files.
Practically, there's no limitation on the file size in the exFAT and NTFS file systems.
Linux's EXT4 and Apple's APFS support files up to 16 TiB and 8 EiB respectively.
File Explorers
As you know, the logical layer of the file system provides an API to enable user applications to perform file operations, such as read, write, delete, and execute.
The file system's API is a low-level mechanism, though, designed for computer programs, runtime environments, and shells - not designed for daily use.
That said, operating systems provide convenient file management utilities out of the box for your day-to-day file management. For instance, File Explorer on Windows, Finder on Mac OS, and Nautilus on Ubuntu are examples of file explorers.
These utilities use the logical file system's API under the hood.
Apart from these GUI tools, operating systems expose the file system's APIs via the command-line interfaces as well, like Command Prompt on Windows, and Terminal on Mac and Linux.
These text-based interfaces help users do all sorts of file operations in the form of text commands. Just like how we did in the previous examples.
File access management
Not everyone should be able to remove or modify a file they don't own or update files if they are not authorised to do so.
Modern file systems provide mechanisms to control users' access and capabilities with regard to files.
The data regarding user permissions and file ownership is stored in a data structure, called Access-Control List (ACL) on Windows, or Access-Control Entries (ACE) on Unix-like operating systems (Linux and Mac OS).
This feature is also available in the CLI, where a user can change file ownerships, or limit permissions of each file right from the command line interface.
For instance, a file owner (on Linux or Mac) can set a file to be available to the public, like so:
chmod 777 myfile.txt 777 means everyone can do every operation (read, write, execute) on myfile.txt.
Maintaining data integrity
Let's suppose that you've been working on your thesis for a month now. One day you open the file, make some modifications, and save it.
Once you save the file, your word processor program sends a "write" request to the file system's API (the logical file system).
The request is eventually passed down to the physical layer to store the file on a number of blocks.
But what if the system crashes while the older version of the file is being replaced with the new version?
Well, in older file systems (like FAT32 or ext2) the data would be corrupted because it was partially written to the disk.
However, this is less likely to happen with modern file systems as they use a technique called journaling.
Journaling file systems record every single operation that's about to happen in the physical layer but hasn't happened yet.
The main purpose is to keep track of the changes that haven't yet been committed to the file system physically.
The journal is a special allocation on disk where each write attempt is first stored as a transaction.
Once the data is physically placed on the storage device, the change is committed to the filesystem.
In case of a system failure, the file system will detect the incomplete transaction and rolls it back as if it never happened.
That said, the new content (that was being written) may still be lost, but the existing data would remain intact.
Modern file systems such as NTFS, APFS, and EXT4 (even EXT3) use journaling to avoid data corruption in case of system failure.
Database File Systems
Typical file systems organise files as directories.
To access a file, you traverse to the respective directory and you have it.
cd /music/country/highwayman However, in a database file system, there's no concept of paths and directories.
The database file system is a faceted system which groups files based on various attributes and dimensions.
For instance, MP3 files can be listed by artist, genre, release year, and album - at the same time!
A database file system is more like a high-level application to help you organise and access your files more easily and more efficiently. However, you won't be able to access the files outside of this application.
A database file system cannot replace a typical file system, though. It's just a high-level abstraction to handle files efficiently
The iTunes app on Mac OS is a good example of a database file system.
Wrapping Up
Wow! You made to the end, which means you now know a lot more about file systems. But I'm sure this won't be the end of your file system studies.
So again - can we describe what a file system is and how it works in one sentence?
Let's finish this post with the brief description I used at the beginning:
A file system defines how files are named, stored, and retrieved from the storage device.
If there's something that you think is missing or that I've gotten wrong, please let me in the comments below.
By the way, if you like more detailed content like this, visit my web site skillupp.tech and follow me on Twitter, because these are the channels I use to share my everyday findings.
Thanks for reading and enjoy learning!
Learn to code for free. freeCodeCamp's open source curriculum has helped more than 40,000 people get jobs as developers. Get started
Software Is Used in a Linux Environment to Mount and Write Data Only to Ntfs Partitions
Source: https://www.freecodecamp.org/news/file-systems-architecture-explained/
0 Response to "Software Is Used in a Linux Environment to Mount and Write Data Only to Ntfs Partitions"
إرسال تعليق